
Most fundamental in dealing with Unicode characters — whether in interactions with files, webpages, or in database access — is proper use of character encoding. Once the character encoding has been properly configured, programming Unicode, or international, applications becomes a transparent process. For example, in writing Unicode characters to a text file, you need to specify a Unicode encoding for the file to avoid loss of data; when reading back, you need to use the same encoding to decode what you wrote. For database applications, you need to ensure the database encoding is properly configured so that it can accept storage of Unicode data. For instance, SQL Server 2000 uses UTF-16 as its encoding, while MySQL server's encoding can be set to UTF-8 to handle international characters. Once configured properly, programming should be straight forward; Unicode characters will be handled correctly and automatically between the Java applications and the servers.
You can directly type Vietnamese in Java source code using any appropriate Vietnamese input methods, save them in a Unicode Transformation Format, such as UTF-8, and then specify the appropriate encoding when compiling them. Or you can escape them by using native2ascii tool supplied with JDK. The main advantage of using Unicode escape sequences is that the source is independent of file encoding, but at the expense of code readability and modifiability.
Note: When saving in UTF-8 format, be sure to use an editor that does not emit BOM (byte order mark) signature at the beginning of the file. The BOM characters will cause javac compiler to fail. For instance, Windows Notepad is one of such editors, while jEdit or JCreator is not.
/* // EFBBBF is UTF-8 BOM signature; needs to be removed from the source code
* NewMain.java
*
* Source saved in UTF-8 format
*/
import javax.swing.JOptionPane;
public class NewMain {
public static void main(String[] args) {
JOptionPane.showMessageDialog(null, "Thử nghiệm Tiếng Việt", "Tiếng Việt", JOptionPane.INFORMATION_MESSAGE);
}
}
When compiling the source, be sure to specify the appropriate encoding:
javac -encoding utf8 NewMain.javaIf the Unicode characters have been escaped (by native2ascii tool), no specification of encoding is necessary.
native2ascii -encoding utf8 NewMain.java NewMain.java
If you run your program on a Java virtual machine (JVM) prior to Tiger (1.5 or 5.0), you will need to modify the font.properties file under the jre/lib directory to enable display of Vietnamese characters.
Followed is how to set the default file encoding to UTF-8 in common Java integrated development editors (IDE). Be sure to change the editor font to a Unicode font, such as Courier New, to enable display of Unicode characters in the source code.
Window > Preferences... > General > Appearance > Colors and Fonts: Courier New
Window > Preferences... > General > Editors > Text file encoding: UTF-8

Tools > Options > Editing > Editor Setting > Java Editor > Fonts and Color: Courier New
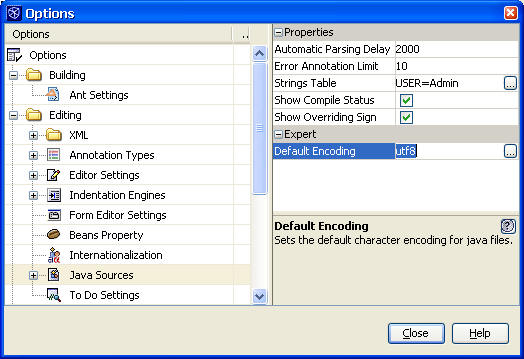
Tools > Options > Editing > Java Sources: Default Encoding: utf8

Utilities > Global Options... > Text Area > Text font: Courier New
Utilities > Global Options... > General > Default character encoding: UTF-8

Configure > Options > Documents/Java/Fonts: Courier New
Configure > Options > Documents/Java/Encoding: No encoding
Project > Project Properties > JDK Tools, select Default > Edit > Parameters > Parameters > JAVAC > -encoding <encoding>, then replace <encoding> with utf8 for each project; or repeat Configure > Options > JDK Tools,... -encoding utf8 to make it default for all projects.

References:
![]()